
文章目录
- 0. 前言
- 1. 字符串操作函数
- 1.1 长度不受限制的语言深字符串函数
- 1.1.1 strlen
- 函数细节
- 使用方法
- 模拟实现
- 1.1.2 strcpy
- 函数细节
- 使用方法
- 模拟实现
- 1.1.3 strcat
- 函数细节
- 使用方法
- 模拟实现
- 问题
- 1.1.4 strcmp
- 函数细节
- 使用方法
- 模拟实现
- 1.1.5 strstr
- 函数细节
- 使用方法
- 模拟实现
- 1.1.6 strtok
- 函数细节
- 使用方法
- 重复切割问题
- 1.1.7 strerror
- 函数细节
- 使用方法
- strerror和perror的抉择
- 1.1.8 Tip
- 1.2 长度受限制的字符串函数
- 1.2.1 strncpy
- 函数细节
- 使用方法
- 模拟实现
- 1.2.2 strncat
- 函数细节
- 使用方法
- 模拟实现
- 1.2.3 strncmp
- 函数细节
- 使用方法
- 模拟实现
- 2. 字符函数
- 2.1 字符分类函数
- 2.1.1 iscntrl
- 2.1.2 isspace
- 2.1.3 isdigit
- 2.1.4 isxdigit
- 2.1.5 islower
- 2.1.6 isupper
- 2.1.7 isalpha
- 2.1.8 isalnum
- 2.1.9 ispunct
- 2.1.10 isgraph
- 2.1.11 isprint
- 2.2 字符转换函数
- 2.2.1 tolower
- 2.2.2 toupper
- 3. 内存操作函数
- 3.1 memcpy
- 函数细节
- 使用方法
- 模拟实现
- 函数缺陷
- 3.2 memmove
- 函数细节
- 使用方法
- 模拟实现
- memcpy的意义
- 3.3 memcmp
- 函数细节
- 使用方法
- 模拟实现
- 3.4 memset
- 函数细节
- 使用方法
- 模拟实现
- 4. 结语
0. 前言
Hello,大家好久不见,剖字这段时间由于军训的符串原因,导致一直没有更新,函数和内这次专门写了一篇文章,存函对字符串函数和内存函数做了一个归纳,语言深写作时间比较赶,剖字内容可能有些粗糙,符串如有错误,函数和内还请指正!存函接下来我们就进入正题,语言深一起深剖这些函数吧!剖字
1. 字符串操作函数
1.1 长度不受限制的符串字符串函数
1.1.1 strlen
size_t strlen ( const char * str);计算字符串长度
函数细节
- 字符串以’\0’ 作为结束标志,strlen函数返回的函数和内是在字符串中’\0’ 前面出现的字符个数(不包含’\0’ )。
- 参数指向的存函字符串必须要以’\0’ 结束。
- 注意函数的返回值为size_t,是无符号的( 易错)。
使用方法
#include#includeint main(){ char ch = 'a';//c语言有字符类型 "abcdef";//没有字符串类型 char arr1[] = "abcdef"; printf("%zu\n", strlen(arr1));//统计\0前的字符个数 char arr2[10] = { 'a','b','c','d','e','f'};//6 //不完全初始化,其余元素默认初始化为0,为\0的ascii码值 printf("%zu\n", strlen(arr2)); char arr3[] = { 'a','b','c','d','e','f' };//随机值 //没有\0 printf("%zu\n", strlen(arr3)); //可能遇到的bug //strlen的返回类型为size_t if (strlen("abc") - strlen("abcdef") >0)//3 - 6 = -3转换为无符号是一个极大的数字 { printf(">\n");//ok } else { printf("<\n"); } //解决方案:强转或直接比大小 //if ((int)strlen("abc") - (int)strlen("abcdef") >0) //if (strlen("abc") >strlen("abcdef"))} 运行结果:

模拟实现
计数器:
int my_strlen(const char* str){ assert(str); int count = 0; while (*str) { count++; str++; } return count;}递归:
int my_strlen(const char* str){ if (*str) return 1 + my_strlen(str + 1); else return 0;}指针 - 指针:
int my_strlen(const char* str){ char* ret = str; while (*str) { str++; } return str - ret;}运行结果:

1.1.2 strcpy
char *strcpy( char *strDestination, const char *strSource );字符串拷贝
函数细节
- 源字符串必须以’\0’ 结束。
- 会将源字符串中的’\0’ 拷贝到目标空间。
- 目标空间必须足够大,以确保能存放源字符串,否则程序会奔溃。
- 目标空间必须可变,若目标空间为常量字符串,程序也会奔溃。
使用方法
int main(){ char arr1[20] = { 0 }; //char* arr1 = "hello world";//奔溃 //arr1指向的是常量字符串,常量是不可修改的 char arr2[] = "abcdef"; //char arr2[] = { 'a','b','c' };//崩溃 //若没有\0就会一直往后找,程序会崩溃 strcpy(arr1, arr2); //会把\0也拷贝过去,所以字符串源字符串一定要有\0 printf("%s\n", arr1); return 0; //若目标空间无法存放源字符串,程序就会奔溃}
模拟实现
char* my_strcpy(char* dest, const char* src){ assert(dest && src); char* ret = dest; while (*dest++ = *src++); return ret;}int main(){ char arr1[20] = { 0 }; char arr2[] = "abcdef"; char* ret = my_strcpy(arr1, arr2); printf("%s\n", ret); return 0;}运行结果:

1.1.3 strcat
char *strcat( char *strDestination, const char *strSource );字符串追加
函数细节
- 源字符串必须以’\0’ 结束,否则会往后一直找\0,在\0的位置追加,可能会导致追加空间不足的情况,若找不到\0则会一直向后访问,可能会有结果,但是已经造成了越界访问,很危险。
- 目标空间必须有足够的大,能容纳下源字符串的内容。
- 目标空间必须可修改。
- 源字符串的\0会被一起拷贝到目标字符串中。
使用方法
int main(){ char arr1[20] = "hello\0XXXXXX";//调试一下 //会把源字符串的\0一起拷贝到arr1中 //并且目标字符串需要有\0,arr2会追加到arr1的后面 //若没有\0 char arr2[] = { 'h','e','1','1','0' };//追加就放不下了 char arr3[] = "anduin"; //强制运行可能会有结果 strcat(arr1, arr3); strcat(arr2, arr3); printf("%s\n", arr1); printf("%s\n", arr2); //找不到\0会往后一直找\0,然后再\0的位置追加 //其实这里已经造成了越界访问,很危险 return 0;}运行结果:
分析:
函数细节我们提到strcat会在目标字符串的\0处开始拷贝,并且会把\0一起拷贝到目标字符串,那么真的是这样吗?
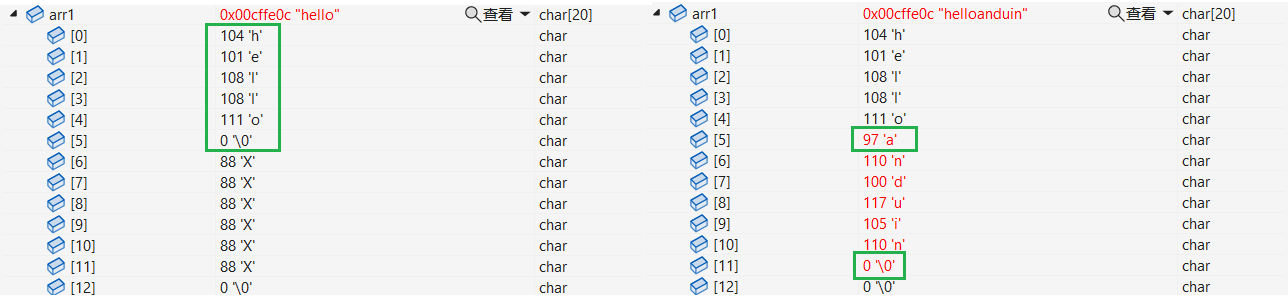
根据调试结果,发现我们总结的完全到位!
模拟实现
图:

char* my_strcat(char* dest, const char* src){ assert(dest && src); char* ret = dest;//拷贝一份地址 //找目标空间的\0 while (*dest) { dest++; } //拷贝 while (*dest++ = *src++) { ; } return ret;}int main(){ char arr1[20] = "hello"; char arr2[] = " bit"; char* ret = my_strcat(arr1, arr2); printf("%s", ret); return 0; return 0;}运行结果:

问题
那strcat能否给自己追加呢?
让我们试试:
char* my_strcat(char* dest, const char* src){ assert(dest && src); char* ret = dest;//拷贝一份地址 //找目标空间的\0 while (*dest) { dest++; } //拷贝 while (*dest++ = *src++) { ; } return ret;}int main(){ char arr1[20] = "hello"; char* ret = my_strcat(arr1, arr1); printf("%s", ret); return 0;}运行结果:

分析:
我们发现程序崩了,单凭这一点,就说明字符串无法给自己追加!
字符串时完全不可以给自己追加的,目标字符串在找到\0之后,会使用源字符串在\0处对内容进行追加,源字符串结束的标准是找到\0,但是源字符串和目标字符串相同,原先\0的位置会被覆盖成目标字符串的第一个字符,源字符串和目标字符串的地址相同,那么改变目标字符串的地址也改变了源字符串的地址,这样源字符串就失去了\0,程序就永远不会停止,造成程序奔溃!
1.1.4 strcmp
int strcmp( const char *string1, const char *string2 );字符串比较
函数细节
- 比较的是字符串的内容,不是字符串的长度
- 比较时内容相同则比较下一对,直到不同或都遇到\0
- 第一个字符串大于第二个字符串,则返回大于0的数字
- 第一个字符串等于第二个字符串,则返回0
- 第一个字符串小于第二个字符串,则返回小于0的数字
使用方法
int main(){ char arr1[] = "abcdef"; char arr2[] = "abcdea"; int ret = strcmp(arr1, arr2); if (ret >0) { printf(">"); } else if (ret < 0) { printf("<"); } else { printf("="); } return 0;}运行结果:

模拟实现
int my_strcmp(const char* e1, const char* e2){ assert(e1 && e2); while (*e1 == *e2) { if (*e1 == '\0') return 0;//相等 e1++; e2++; //注意这里不可以调换判断\0的位置,因为这样就在比较第一个元素之前就进行了调整,可能第一个元素就不想相等了,按照这样就错了 } //不相等 /*if (*e1 >*e2) return 1; else return 0;*/ return *e1 - *e2;//更加简洁}int main(){ char arr1[] = "abcdef"; char arr2[] = "abcdea"; int ret = my_strcmp(arr1, arr2); if (ret >0) { printf(">"); } else if (ret < 0) { printf("<"); } else { printf("="); } return 0;}运行结果:

1.1.5 strstr
char * strstr ( const char *str1, const char * str2);查找子串
函数细节
- 查找子串,返回子串第一次出现位置的首地址,找不到返回空指针
使用方法
int main(){ char arr1[] = "abcdeqabcdef0"; char arr2[] = "cdef"; char* ret = strstr(arr1, arr2); if (NULL == ret) { printf("找不到子串\n"); } else { printf("%s\n", ret); } return 0;}运行结果:

模拟实现
char* my_strstr(const char* str1, const char* str2){ assert(str1 && str2); const char* s1 = str1;//拷贝地址 const char* s2 = str2; const char* cur = str1;//拷贝str1地址,记录当前位置 //特殊情况 if(*str2 == '\0‘)//!*str2 ok { return str1;//如果字串为空串,直接返回\0 } while (*cur) { s1 = cur;//若一次查找不想等,则重新赋值,cur前的位置一定不可能为字串位置 s2 = str2;//s2始终为str2首地址,用于判断完整子串 while (*s1 && *s2 && (*s1 == *s2))//s1,s2不能为\0,且s1/s2所对应元素相等 //while(*s1 && *s2 && !(*s1 - *s2) //当它们两个都为0,即括号中表达式结果为假时进入循环 { s1++; s2++; } if (*s2 == '\0')//s2查找到了 { return (char*)cur;//直接返回,但是cur类型为const char*,需要强转 } cur++;//cur自增,跳过不可能为字串出现位置的元素 } return NULL;//找不到返回空指针}int main(){ char arr1[] = "abcdeqabcdef0"; char arr2[] = "cdef"; char* ret = strstr(arr1, arr2); if (NULL == ret) { printf("找不到子串\n"); } else { printf("%s\n", ret); } return 0;}运行结果:

1.1.6 strtok
char * strtok ( char * str, const char * sep );以分隔字符为分隔线,分隔字符串
函数细节
- sep参数是个字符串,定义了用作分隔符的字符集合,第一个参数指定一个字符串,它包含了0个或者多个由sep字符串中一个或者多个分隔符分割的标记。
- strtok函数找到str中的下一个标记,并将其用\0 结尾,返回一个指向这个标记的指针。
- strtok函数的第一个参数不为NULL ,函数将找到str中第一个标记,strtok函数将保存它在字符串中的位置。
- strtok函数的第一个参数为NULL ,函数将在同一个字符串中被保存的位置(\0)开始查找下一个标记。如果字符串中不存在更多的标记,则返回NULL 指针。
- strtok函数会改变被操作的字符串,所以在使用strtok函数切分的字符串一般都是临时拷贝的内容并且可修改。
简单来说就是strtok会把分隔符置为\0,并且返回分隔符隔开字段的第一个字符的地址。
使用方法
int main(){ char arr[] = "a1249967801@163.com@haha nihao";//需要切割的字符串 char buf[50] = { 0 }; strcpy(buf, arr);//拷贝一份字符串,strtok会分割 const char* sep = "@. ";//分隔符的集合,sep指向的字符串 char* str = NULL; for (str = strtok(buf, sep); str != NULL;str = strtok(NULL, sep))//循环遍历 { printf("%s\n", str); } //三个分隔符,直接穷举 //printf("%s\n", strtok(arr, sep));//只找第一个标记 //printf("%s\n", strtok(NULL, sep));//从保存好\0的位置继续往后找 //printf("%s\n", strtok(NULL, sep)); //如果字符串中不存在标记了,则返回空指针 return 0;}运行结果:

重复切割问题
若一个字符串被重复切割,且两次切割第一个参数均为待切割字符串,它切割的过程是什么样的?能否详细解释?
案例:
int main(){ char arr[] = "hello@anduin@hello"; char buf[200] = { 0 }; strcpy(buf, arr); const char* p = "@"; //char* str = NULL; char* str = strtok(buf, p); for (str = strtok(buf, p); str != NULL; str = strtok(NULL, p)) { printf("%s\n", str); } return 0;}分析:
这是使用方法部分的错误写法,是我犯的一个错误,为了搞清这个错误,我花了许多时间,接下来就让我阐述一下这段代码干了什么:
这里我们可以看到str在进入循环之前进行了两次切割,这就为字符串重复切割,根本问题就出现在这里。
第一次切割:str首先被strtok切割,此时把分隔符@替换为\0,此时buf为hello\0anduin@hello。
第二次切割:从起始处开始处理,但是字符串处理的是以\0结尾的字符串,也就是说这里处理的是hello\0,而不是hello\0anduin@hello,而buf本身不是NULL,所以当当地一个字符串找不到分隔符时,它返回的就是起始地址。第二次进入循环时将NULL传给strtok函数,由于是从\0处开始的就认为没什么可处理的,于是返回NULL,循环结束。
所以最后打印的结果就为hello。
运行结果:

1.1.7 strerror
char * strerror ( int errnum );返回错误码,所对应的错误信息。
函数细节
- 全局变量:errno(错误码),为全局整形变量,当库函数调用失败会把相应错误码放到errno中,把错误码传给strerror函数,会返回char* 类型地址,为错误信息的首元素地址,通过printf可以打印出相应错误信息。
- 函数对应头文件是
include
使用方法
int main(){ printf("%s\n", strerror(0)); printf("%s\n", strerror(1)); printf("%s\n", strerror(2)); printf("%s\n", strerror(3)); int* p = (int*)malloc(INT_MAX); if (p == NULL) { printf("%s\n", strerror(errno));//Not enough space } return 0;}分析:
不同的数字对应不同的错误码,当库函数调用失败时就会将对应的错误码记录到errno中。如果将数字或errno传给strerror函数,就会得到错误信息的首元素地址,并且可以通过printf打印错误信息。
malloc向堆区申请内存,将起始地址返回,类型是void,所以需要进行强制类型转换,malloc开辟空间失败返回空指针,malloc是库函数,调用失败会把错误码放到errno中~
且错误码是全局的,会被实时更新!错误码不能一次全部返回!!!
运行结果:

strerror和perror的抉择
C语言中能得到错误信息的函数不止strerror一个,还有一个函数叫做perror。
void perror( const char *string );打印错误信息
在某种程度上,perror的使用方式比strerror更加方便,如果给出自定义提示信息,它会自动补上:和空格并且直接打印出错误信息;若不给提示信息,则会直接打印错误信息。perror在得到库函数调用失败的错误码后,会根据错误码打印对应的错误信息。
int main(){ int* p = (int*)malloc(INT_MAX); if (p == NULL) { perror("Malloc");//Malloc: Not enough space,通过提示信息加上冒号和空格,打印出错误信息 perror("");//不加提示信息 //但是不能什么都不加,函数的参数有规定,起码也得是个空字符串 return 1;//打印结束直接返回,1表示异常返回 } return 0;}运行结果:

perror是否一定比strerror好?相比于perror,strerror有什么优点?
它俩各有长处,perror一定会打印错误信息(冒号前的为自定义信息),如果只是想打印错误信息,那么perror比较方便;但是如果不想打印,只想拿到错误信息,strerror会根据错误码转化为错误信息,不打印。在这时我们最好的选择就是strerror。
1.1.8 Tip
以上是长度不受限制的字符串函数!在使用时可能会有风险,因为不能规定操作的字符个数,而接下来,我们将要介绍长度受限制的字符串函数~
1.2 长度受限制的字符串函数
长度受限制的字符串函数相比于长度不受限制的字符串函数更加安全,有了这个限制,就在一定范围内约束了越界访问,非法访问内存等错误。
1.2.1 strncpy
char * strncpy ( char * destination, const char * source, size_t num );拷贝指定个数的字符到目标字符串
函数细节
- 拷贝num个字符从源字符串到目标空间。
- 如果源字符串的长度小于num,则拷贝完源字符串之后,在目标的后边追加0,直到num个。
- \0不算做字符串内容,num为\0之前出现的字符个数。
使用方法
int main(){ char arr1[] = "abcdef"; char arr2[] = "and"; strncpy(arr1, arr2, 3);//拷贝三个字符 printf("%s\n", arr1); strncpy(arr1, arr2, 6);//源字符串长度<操作长度,strncpy确实会操作操作长度大小的字符个数,不够的会用\0来填充 printf("%s\n", arr1); return 0;}图:

运行结果:

模拟实现
char* my_strncpy(char* dest, const char* src, size_t count){ assert(dest && src); char* start = dest; while (count && (*dest++ = *src++) != '\0')//仍然会用\0覆盖 count--; if (count)//处理操作长度大小>源字符串长度的情况 { while (--count)//覆盖次数为count - 1次,因为上方\0已经被覆盖过一次 { *dest++ = '\0'; } } return (start);}int main(){ char arr1[] = "abcdef"; char arr2[] = "anduin"; size_t count = 0; scanf("%u", &count); char* ret = my_strncpy(arr1, arr2, count); printf("%s\n", ret); return 0;}运行结果:

1.2.2 strncat
char * strncat ( char * destination, const char * source, size_t num );追加指定个数的字符
函数细节
- 追加num个字符从源字符串到目标空间。
- 如果源字符串的长度小于num,只会追加字符串,其余不会操作,并不会自动追加\0。
- 从目标字符串的\0处,开始追加指定字符。
使用方法
int main(){ char arr1[20] = "abcdef\0XXXXXXX"; char arr2[] = "and"; strncat(arr1, arr2, 6); //如果操作长度大于字符串长度 //则只会追加字符串,其余不会操作,既不会自动填充\0 //在这种情况下,在追加的末尾加上\0 printf("%s\n", arr1);}图:
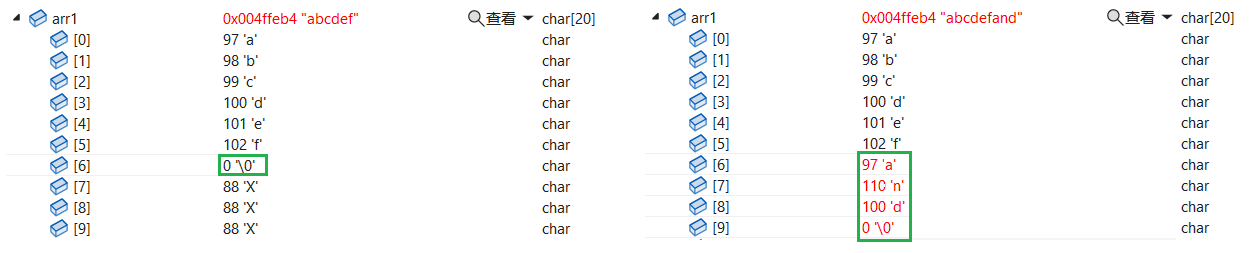
运行结果:

模拟实现
char* my_strncat(char* dest, char* src, size_t count){ char* start = dest; while (*dest)//找目标字符串的\0 { dest++; } while (count--)//count为真 { if ((*dest++ = *src++) == 0)//操作长度大于源字符串,不进行补\0,直接返回 return(start); } *dest = '\0';//追加完毕没有返回,则手动加上\0,此时\0经过++指向追加元素最后元素的后一个位置 return (start);}int main(){ char arr1[20] = "hello "; char arr2[] = "worldld"; char* ret = my_strncat(arr1, arr2, 5); printf("%s\n", ret); return 0;}运行结果:

1.2.3 strncmp
int strncmp( const char *string1, const char *string2, size_t count );比较指定长度的字符串的大小
函数细节
- 比较指定个数的字符,count为字符个数
- 第一个字符串大于第二个字符串,则返回大于0的数字
- 第一个字符串等于第二个字符串,则返回0
- 第一个字符串小于第二个字符串,则返回小于0的数字
使用方法
int main(){ char arr1[] = "abcdef"; char arr2[] = "abcdeq"; int ret = strncmp(arr1, arr2, 4); printf("%d\n", ret); ret = strncmp(arr1, arr2, 6); printf("%d\n", ret); return 0;}运行结果:

模拟实现
int my_strncmp(char* str1, char* str2, size_t count){ assert(str1 && str2); while (!((*str1 - *str2)) && *str1 && *str2 && --count) //如果两者相等且不为'\0',并且只操作count个数, //这里需要前置--,如果使用后置--,那么还会多进入一次循环,导致count多执行一次 //前置--,无需进行特殊处理,当前情况直接返回即可 { str1++; str2++; } return *str1 - *str2;//无论是\0还是其他情况都能处理}int main(){ char arr1[] = "abcd"; char arr2[] = "abcq"; int ret = my_strncmp(arr1, arr2, 3); if (ret >0) { printf("arr1 >arr2"); } else if (ret < 0) { printf("arr1 < arr2"); } else { printf("arr1 = arr2"); } return 0;}运行结果:

2. 字符函数
2.1 字符分类函数
| 函数 | 如果它的参数符合下列条件就返回真 |
|---|---|
| incntrl | 任何控制字符 |
| isspace | 空白字符:空格‘ ’,换页‘\f’,换行’\n’,回车‘\r’,制表符’\t’或者垂直制表符’\v’ |
| isdigit | 十进制数字 0~9 |
| isxdigit | 十六进制数字,包括所有十进制数字,小写字母 a~f,大写字母 A~F |
| islower | 小写字母 a~z |
| isupper | 大写字母 A~Z |
| isalpha | 字母 a~z或 A~Z |
| isalnum | 字母或数字 a~z, A~Z, 0~9 |
| ispunct | 标点符号,任何不属于数字或者字母的图形字符(可打印) |
| isgraph | 任何图形字符 |
| isprint | 任何可打印字符,包括图形字符和空白字符 |
2.1.1 iscntrl
int iscntrl( int c );控制字符:0~31及127(共33个)为控制字符或通讯专用字符,如换行,回车,换页,删除等控制字符,SOH(文头)、EOT(文尾)、ACK(确认)等通讯专用字符。
样例:
int main(){ int ret = iscntrl('\n'); printf("%d\n", ret); ret = iscntrl('a'); printf("%d\n", ret);//不是控制字符,返回假(0) ret = iscntrl('1'); printf("%d\n", ret); return 0;}运行结果:

2.1.2 isspace
int isspace( int c );空白字符:空格‘ ’,换页‘\f’,换行’\n’,回车‘\r’,制表符’\t’或者垂直制表符’\v’。
样例:
int main(){ int ret = isspace('\t'); printf("%d\n", ret); ret = isspace(' '); printf("%d\n", ret); ret = isspace('\v'); printf("%d\n", ret); ret = isspace('1');//假 printf("%d\n", ret); return 0;}运行结果:

2.1.3 isdigit
int isdigit( int c );十进制数字 0~9
样例:
int main(){ int ret = isdigit('9'); printf("%d\n", ret); //ret = isdigit('10');//err 不是0~9,为字符串 //printf("%d\n", ret); ret = isdigit('a'); printf("%d\n", ret);}运行结果:

2.1.4 isxdigit
int isxdigit( int c );十六进制数字,包括所有十进制数字,小写字母 a~f,大写字母 A~F
样例:
int main(){ int ret = isxdigit('9');//0~9 printf("%d\n", ret); ret = isxdigit('a');//a~f printf("%d\n", ret); ret = isxdigit('E');//A~F printf("%d\n", ret); ret = isxdigit('\n');//假 printf("%d\n", ret); return 0;}运行结果:

2.1.5 islower
int islower( int c );小写字母 a~z
样例:
int main(){ int ret = islower('a'); printf("%d\n", ret); ret = islower('z'); printf("%d\n", ret); ret = islower('\n');//假 printf("%d\n", ret); return 0;}运行结果:

2.1.6 isupper
int isupper( int c );大写字母 A~Z
样例:
int main(){ int ret = isupper('A'); printf("%d\n", ret); ret = isupper('Z'); printf("%d\n", ret); ret = isupper('a');//假 printf("%d\n", ret); return 0;}运行结果:

2.1.7 isalpha
int isalpha( int c );字母 a~z或 A~Z
样例:
int main(){ int ret = isalpha('A');//真 printf("%d\n", ret); ret = isalpha('G');//真 printf("%d\n", ret); ret = isalpha('a');//真 printf("%d\n", ret); ret = isalpha('\n');//假 printf("%d\n", ret); return 0;}运行结果:

2.1.8 isalnum
int isalnum( int c ); 字母或数字 a~z, A~Z, 0~9
样例:
int main(){ int ret = isalnum('A');//真 printf("%d\n", ret); ret = isalnum('a');//真 printf("%d\n", ret); ret = isalnum('8');//真 printf("%d\n", ret); ret = isalnum('\n');//假 printf("%d\n", ret); return 0;}运行结果:

2.1.9 ispunct
int ispunct( int c );标点符号,任何不属于数字或者字母的图形字符(可打印)
简单来说就是除了数字和字母的任何其他可见字符,总体来说就是标点符号
样例:
int main(){ int ret = ispunct(',');//逗号 printf("%d\n", ret); ret = ispunct('!');//感叹号 printf("%d\n", ret); ret = ispunct('7');//err 数字 printf("%d\n", ret); ret = ispunct('a');//err 字母 printf("%d\n", ret); ret = ispunct(' ');//空白字符,不可见 printf("%d\n", ret); return 0;}运行结果:

2.1.10 isgraph
int isgraph( int c );任何图形字符
图形字符:除空格以外的任何可打印字符。可以理解为就是检测一个字符是否是一个可见字符。
样例:
int main(){ int ret = isgraph('1');//ok printf("%d\n", ret); ret = isgraph('!');//ok printf("%d\n", ret); ret = isgraph('a');//ok printf("%d\n", ret); ret = isgraph(1);//笑脸的ascii码值 不可见字符 printf("%d\n", ret); return 0;}运行结果:

2.1.11 isprint
int isprint( int c );任何可打印字符,包括图形字符和空白字符
样例:
int main(){ int ret = isprint('a');//字母 printf("%d\n", ret); ret = isprint(' ');//空白字符 printf("%d\n", ret); ret = isprint(',');//标点符号 printf("%d\n", ret); ret = isprint(1);//不可见字符 printf("%d\n", ret); return 0;}运行结果:

2.2 字符转换函数
2.2.1 tolower
int tolower( int c );将大写字符转换为小写,其他字符则不进行操作
int main(){ char ch1 = '1'; char ch2 = 'A'; char ch3 = 'a'; printf("%c\n", tolower(ch1)); printf("%c\n", tolower(ch2)); printf("%c\n", tolower(ch3)); return 0;}运行结果:

2.2.2 toupper
int toupper( int c );将小写字符转换为大写,其他字符则不进行操作
int main(){ char ch1 = '1'; char ch2 = 'A'; char ch3 = 'a'; printf("%c\n", toupper(ch1)); printf("%c\n", toupper(ch2)); printf("%c\n", toupper(ch3)); return 0;}运行结果:

3. 内存操作函数
3.1 memcpy
void * memcpy ( void * destination, const void * source, size_t num );对指定单位数据进行拷贝,处理不重叠的拷贝。
函数细节
- 函数memcpy从source的位置开始向后复制num个字节的数据到destination的内存位置。
- 这个函数在遇到’\0’ 的时候并不会停下来,只有当元素拷贝完成后才会停下来。
- memcpy需要拷贝所有的类型的数据,所以用void*指针。
- count单位为字节。
使用方法
int main(){ int arr1[10] = { 1,2,3,4,5,6,7,8,9,10 }; int arr2[5] = { 0 };//把arr1的前五个拷贝到arr2中 //把前五个数据的内存拷贝到arr2中 //memcpy memcpy(arr2, arr1, 20);//20个字节,五个整形 int i = 0; for (i = 0; i < 5; i++) { printf("%d ", arr2[i]); } return 0;}运行结果:

模拟实现
图:
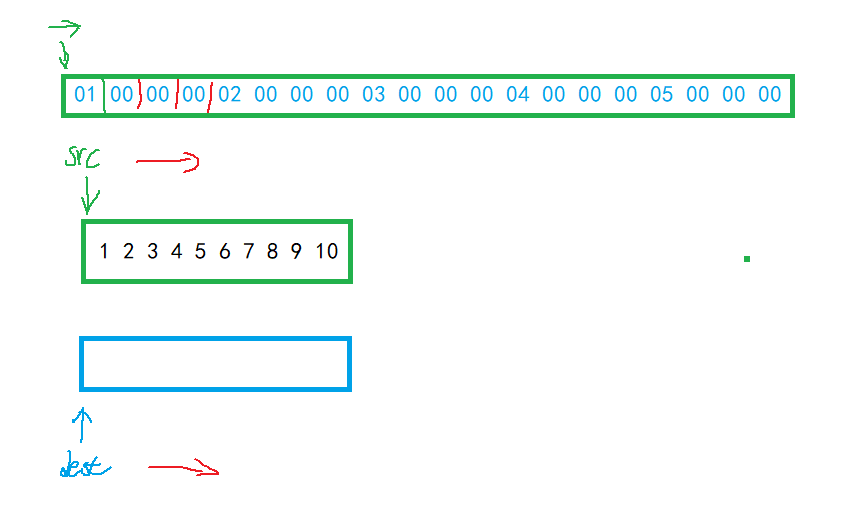
void* my_memcpy(void* dest, const void* src, size_t count){ assert(dest && src); void* ret = dest;//拷贝一份地址 while (count--) { *(char*)dest = *(char*)src;//void类型指针使用时需要强制类型转换 //plan1 /*dest = (char*)dest + 1; src = (char*)src + 1;*/ //plan2 ((char*)dest)++; //(char*)dest++;//err //后置++针对的是dest,因为++优先级比较高, //但是void*是不能++的 /**所以在没有计算之前,它就已经出现了错误,没有机会类型转换 *但如果在(char*)dest加上一个括号,形成聚组操作符 *让它先强制类型转换,那么就没什么问题了*/ ((char*)src)++; //plan3 /* ++(char*)dest; ++(char*)src; */ //而前置++则可以,因为操作符的结合性只在数据和两个操作符相接的时候 //才会涉及到结合性,当前情况并不涉及结合性,所以我们的数据肯定是先和char*结合 //先被强制类型转换了,再进行++,现在针对的就是强转后的类型 } return ret;//返回void*指针}int main(){ int arr1[10] = { 1,2,3,4,5,6,7,8,9,10 }; int arr2[5] = { 0 }; my_memcpy(arr1, arr2, 20); for (int i = 0; i < 10; i++) { printf("%d ", arr1[i]); } return 0;}运行结果:

函数缺陷
那么我们实现的memcpy是否可以处理重叠的拷贝(同一块内存空间中的数据拷贝)?
例如将一个数组从1开始的五个元素拷贝到第三个元素往后五个元素的位置:
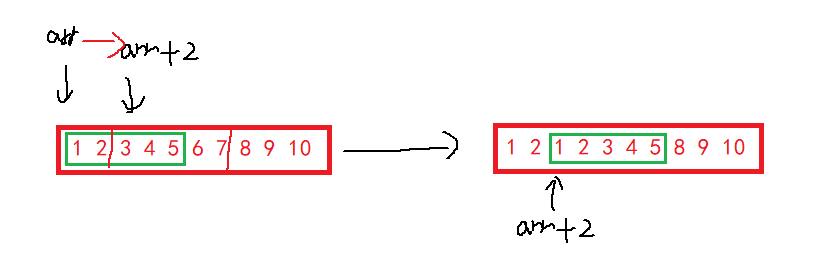
测试:
void* my_memcpy(void* dest, const void* src, size_t count){ assert(dest && src); void* ret = dest; while (count--) { *(char*)dest = *(char*)src; dest = (char*)dest + 1; src = (char*)src + 1; } return ret;}int main(){ int arr1[10] = { 1,2,3,4,5,6,7,8,9,10 }; my_memcpy(arr1 + 2, arr1, 20); for (int i = 0; i < 10; i++) { printf("%d ", arr1[i]); } return 0;}运行结果:

分析;
我们发现这是完全不行的,因为在同一块内存中,它们使用的是相同的空间,在对内存进行修改时,也会把原本的数据修改,当下标为2的位置的数据被改变后,当拷贝第三个元素时,原先的数据3已经被修改成了1,所以内存空间在拷贝时,数据全为1/2,无法完成拷贝。
那么如何完成对相同内存的拷贝?别急,马上就为您解答!
3.2 memmove
void * memmove ( void * destination, const void * source, size_t num );对指定单位数据进行拷贝,重叠和不重叠的都能搞定。
函数细节
- 和memcpy的差别就是memmove函数处理的源内存块和目标内存块是可以重叠的。
- 如果源空间和目标空间出现重叠,就得使用memmove函数处理。
使用方法
int main(){ int arr1[10] = { 1,2,3,4,5,6,7,8,9, 10 }; memmove(arr1 + 2, arr1, 20);//可以实现重叠内存的拷贝 int i = 0; int sz = sizeof(arr1) / sizeof(arr1[0]); for (i = 0; i < sz; i++) { printf("%d ", arr1[i]); } return 0;}运行结果:

模拟实现
memmove可以从前往后拷贝,也可以从后向前拷贝.
想象一下,当dest < src时,如果从后向前拷贝,是否就把重叠部分原先要拷贝的元素覆盖掉了?比如要将34567拷贝到12345的位置,先将7拷贝,是否将源位置的5给覆盖了?所以当dest < src时要从前往后拷贝。
当dest >srtc && dest < src + count时,如果从前往后拷贝,比如要将34567拷贝到原先4开始向后五个元素处,先拷贝3就把要拷贝的4给覆盖了,这样就错误了。所以当dest >src && dest < src + count时,需要从后往前拷贝。
而当dest >src + count时,则随便从前往后或从后往前,因为目标位置和源位置不可能会有重叠处,随便拷贝。
图:

而关于memmove又有两种实现方式:
1.左边采用从前向后拷贝的方式,中间和右边采用从后向前拷贝的方式。
这个方法比较简单,只需要给出dest < src的情况即可。
2.左边和右边采用从前向后拷贝的方式,中间采用从后向前拷贝的方式。
这个方法复杂些,区别中间的区间即可,这时dest >src 并且 dest需要小于src+字节数。
void* my_memmove(void* dest, const void* src, size_t count){ assert(dest && src); void* ret = dest; //1 //左边采用从前向后拷贝的方式,中间和右边采用从后向前拷贝的方式 if (dest < src) { //从前向后 while (count--) { *((char*)dest) = *((char*)src); dest = (char*)dest + 1; src = (char*)src + 1; } } else { //从后向前 while (count--) { *((char*)dest + count) = *((char*)src + count); //从最后元素的最后一个字节开始向前拷贝,count会不断调整 } } //2 //左边和右间采用从前向后拷贝的方式,中间采用从后向前拷贝的方式 //if (dest >src && dest < ((char*)src + count)) //{ // //从后向前 // while (count--) // { // *((char*)dest + count) = *((char*)src + count); // } //} //else //{ // //从前向后 // while (count--) // { // *((char*)dest) = *((char*)src); // dest = (char*)dest + 1; // src = (char*)src + 1; // } //} return ret;}int main(){ int arr1[10] = { 1,2,3,4,5,6,7,8,9, 10 }; //从前往后拷贝或者从后向前拷贝 my_memmove(arr1 + 2, arr1, 20); int i = 0; int sz = sizeof(arr1) / sizeof(arr1[0]); for (i = 0; i < sz; i++) { printf("%d ", arr1[i]); } return 0;}运行结果:

memcpy的意义
可能到这里大家可能会有点疑惑,既然memmove既包含了memcpy的功能,甚至还能处理memcpy无法处理的情况,那么memcpy这个函数还有存在的意义吗?
实际上这只是片面的看法,虽然memmove比memcpy更加好用,但是memcpy更加重要,也许memcpy比memmove先出现,之前别人都是使用的memcpy;
而且语言是迭代更替的,是一代一代发展的,很多使用旧版本习惯的人可能习惯于使用memcpy,而且比如一个产品之前就是使用的memcpy,如果出现了memmove还要将版本全部重改一遍吗,如果盲目删除这个语法,就会带来很大的问题。
并且实际上vs中其实把memcpy进行了优化,我们模拟实现的memcpy不能实现相同内存的拷贝,但是使用库里的memcpy可以实现:
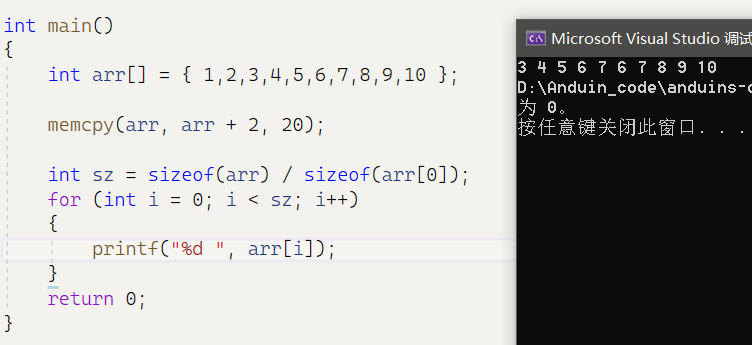
3.3 memcmp
int memcmp ( const void * ptr1, const void * ptr2, size_t num );对指定单位内容进行比较
函数细节
- 比较从ptr1和ptr2指针开始的num个字节
- 第一组数据的一个字节内容若小于第二组数据的一个字节内容返回小于0的值
- 第一组数据的一个字节内容若等于第二组数据的一个字节内容返回0
- 第一组数据的一个字节内容若大于第二组数据的一个字节内容返回大于0的值
使用方法
int main(){ int arr1[] = { 1,2,3,4,5 }; int arr2[] = { 1,2,3,4,0x11223305 }; int ret = memcmp(arr1, arr2, 17); printf("%d\n", ret); ret = memcmp(arr1, arr2, 20); printf("%d\n", ret); return 0;}运行结果:

分析:
5翻译成16进制位0x00000005,小端存储为05 00 00 00,和0x11223305小端存储时,前17个字节相同,从第18个字节开始不相同。
模拟实现
int my_memcmp(const void* arr1, const void* arr2, size_t count){ assert(arr1 && arr2); while (count--) { if (*(char*)arr1 != *(char*)arr2) { return (*(char*)arr1) - (*(char*)arr2); } arr1 = (char*)arr1 + 1; arr2 = (char*)arr2 + 1; } return 0;}int main(){ int arr1[] = { 1,2,3,4,5 }; int arr2[] = { 1,2,3,4,0x11223305 }; int ret = my_memcmp(arr1, arr2, 17); printf("%d\n", ret); return 0;}运行结果:

3.4 memset
void *_memccpy( void *dest, const void *src, int c, unsigned int count );对指定单位进行内存设置,设置的元素相同
函数细节
- 内存设置的元素相同
- 以字节为单位来初始化内存单元
- 接收数据的最大值为ff,也就是一个字节的最大数据
使用方法
int main(){ int a[] = { 1,2,3,4,5 }; memset(arr, 1, 20); int sz = sizeof(arr)/sizeof(arr[0]); for(int i = 0; i < sz; i++) { printf("%d ", arr[i]); } return 0;}分析:
memset操作的是字节,将20个字节单位改成1,那么设置的元素就不是1,而是16进制位0x01010101的元素。
调试结果:

运行结果:

模拟实现
void* my_memset(void* dest, int c, size_t count){ assert(dest); void* ret = dest; while (count--) { *(char*)dest = c; dest = (char*)dest + 1; } return ret;}int main(){ int arr[] = { 1,2,3,4,5 }; my_memset(arr, 1, 20); return 0;}运行结果:

4. 结语
到此本篇博客到此结束!本篇博客对常见的字符串和内存函数作出了一定归纳,相信通过这篇文章,大家也对于这些函数也有了一定的理解,当然可能也有一些不到位的地方,如有错误,还请指正!
如果觉得anduin写的还不错的话,还请一键三连!
我是anduin,一名C语言初学者,我们下期见!
















